
随机性是金融市场的重要特征之一。公司是否对其发行的债务违约,经营、投资项目的到期收益率,未来的资产价格等都是难以预测的。研究这些不确定事件的一般方法是将它们与数值联系起来,然后运用统计量来描述它们的特点。
(一)随机变量
1.定义
我们将一个能取得多个可能值的数值变量盖称为随机变量。比如我们规定对于某A公司发行的债券,定义违约变量:
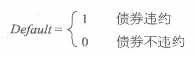
那么Default就是一个随机变量;再比如,A公司发行的普通股股价在未来某一天的收盘价S可以是5元,可以是10元,也可以是5~10元的任意一个数值,于是S同样是一个随机变量。
如果一个随机变量X最多只能取可数的不同值,则为离散型随机变量;如果X的取值无法一一列出,可以遍取某个区间的任意数值,则为连续型随机变量。在上面的例子中,Defailt只能取0或1,因而是离散型随机变量;而S的取值可能是任意一个大于0的数,因而是连续型随机变量。
2.随机变量的分布
如X是离散型的,X最多可能取n个值x1,x2,…,xn,并且记pi=P{X=xi}是X取xi的概率,所有概率的总和
如果X是一个连续型随机变量,由于无法列出X取每个特定值的概率,我们改用概率密度函数来刻画X的分布性质。概率密度函数是用来衡量随机变量X取值在特定范围内的函数,其图像称为概率密度函数曲线。
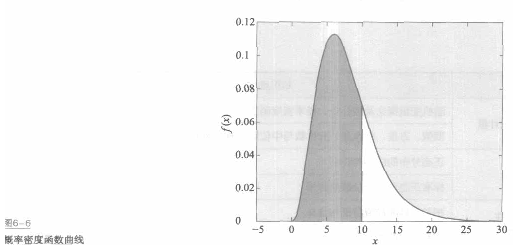
图6-6中画出某连续型随机变量的概率密度函数曲线,其中的阴影部分面积就是该
变量取值在(0,10)的概率P{O
(二)随机变量的数字特征与描述性统计量
知道随机变量的分布之后,我们需要进一步研究分布的特点和规律,比如取值的平均水平、离散程度等。用来衡量这些分布特点的数值统称为数字特征,如均值、方差等。在现实世界里我们面对的随机变量通常是未知分布的,无法直接求得其数字特征,因而我们采取抽样的方法来估计它们,即选择X的一组样本X1,…,Xn,然后构造适当的函数g(X1,…,Xn)来作为x分布的数字特征的近似值,这样的g(X1,…,Xn)便是描述性统计量。常用的一些数字特征和它们的描述性统计量有下面几种。
1.期望(均值)
随机变量X的期望(或称均值,记做E(X))衡量了x取值的平均水平;它是对X所有可能取值按照其发生概率大小加权后得到的平均值。
2.方差与标准差
很多情况下,我们不仅需要了解数据的期望值和平均水平,还要了解这组数据分布的离散程度。分布越散,其波动性和不可预测性也就越强。尤其对于投资者而言,他们不仅关心投资的期望收益率,也关心实际收益率相对预期的收益率可能有多大的偏差,即该投资回报的风险水平。对于投资收益率r,我们用方差(o2)或者标准差(o)来衡量它偏离期望值的程度。
3.分位数
分位数通常被用来研究随机变量X以特定概率(或者一组数据以特定比例)取得大于等于(或小于等于)某个值的情况。
相关推荐: